Blog
A GRPO Experiment: Exploring Emergent Properties
Published April 27, 2026
GRPO (Group Relative Policy Optimization) is a reinforcement learning algorithm that has quietly transformed LLM post-training through its compute-efficient and adaptive architecture.
Last weekend, I explored the emergent properties of GRPO through a research experiment focused on cross-task generalization: the phenomenon where learning one objective drives improvement in another.
GRPO: Visualized
Policy Model
It is the current active learner. The goal is to make it better with reinforcement learning (training without the need for labeled data).
Candidate Answers
For each input prompt, the model generates multiple samples (this is the “Group” in GRPO).
Online Evaluation
Reward Function
For the entire group, calculate individual reward signals for each candidate answer with respect to the objective (a specific skill we want the model to learn).
Reference Model
A frozen version of the original model acts as a stability check. It ensures that as the active policy model learns, its fundamental capabilities do not collapse from the baseline.
Group Comparison
Perform a group comparison by looking at scores relative to one another within the batch. This yields the average score of the group and compares each candidate against that internal baseline (this is the “Relative” in GRPO).
Policy Update
Use these relative signals to update the policy model. The model is encouraged to produce higher-reward answers in the future, while staying close to the reference model to avoid drifting too far from its original capabilities.
Experiment
Hypothesis
“Improving a model’s visual mathematical reasoning can also improve its ability to transcribe LaTeX from images into text.”
Training Setup
Model: Qwen/Qwen3.5-4B
For the base model, I used Qwen3.5-4B. It is a lightweight LLM with native multimodal and reasoning support. The model is small enough to make GRPO experimentation practical, but still benefits from modern pre-training strategies, giving the experiment a strong starting point before reinforcement learning begins.
Dataset: AI4Math/MathVista (testmini split)
The dataset contains math problems grounded in visual scenarios, requiring the model to combine image understanding, mathematical reasoning, and structured problem-solving to arrive at the correct answer.
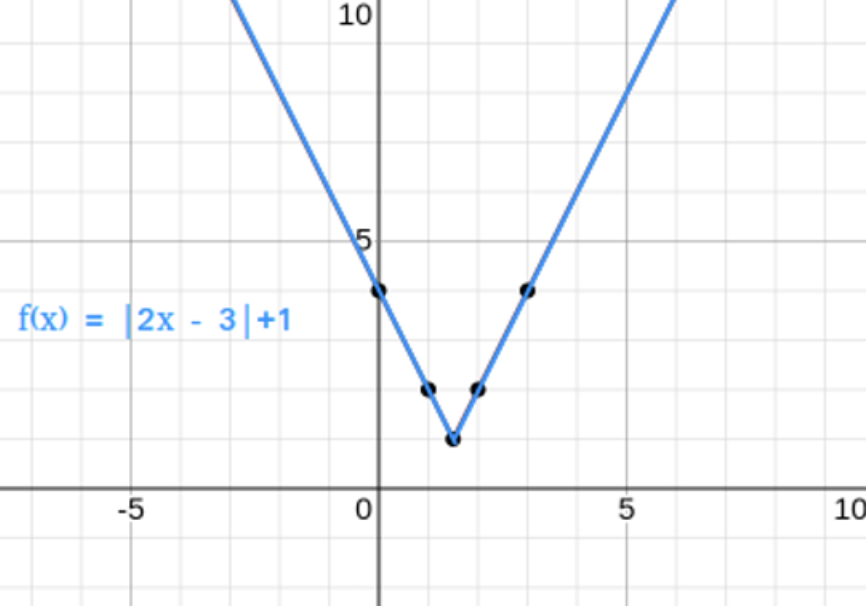
Sample question:
Question: The derivative of f(x) at x=2 is ____ that at x=5
Key Hyperparameters
- LoRA Rank = 16
- LoRA Alpha = 16
- Epochs = 1
- Max Completion Length = 2048
- Optimizer = adamw_8bit
- Answer Group Size = 8
Reward Functions
Formatting Reward
This checks whether the model follows the expected response structure. A good response should contain exactly one reasoning block, one math block, and one final answer block.
Expected format:
<think>Expecting the model to write abstract reasoning here</think>
<math>Here the model is expected to write mathematical formulation</math>
<answer>Final solution</answer>
Correctness Reward
The correctness reward checks whether the final answer matches the ground truth answer from the dataset. If the model places the correct answer inside the solution block, it receives a positive reward.
Thinking Density Reward
This encourages the model to produce a meaningful reasoning section instead of a very short or empty explanation.
Ordering Reward
The ordering reward checks whether the response follows the expected sequence: reasoning -> math -> solution
Training Outcomes
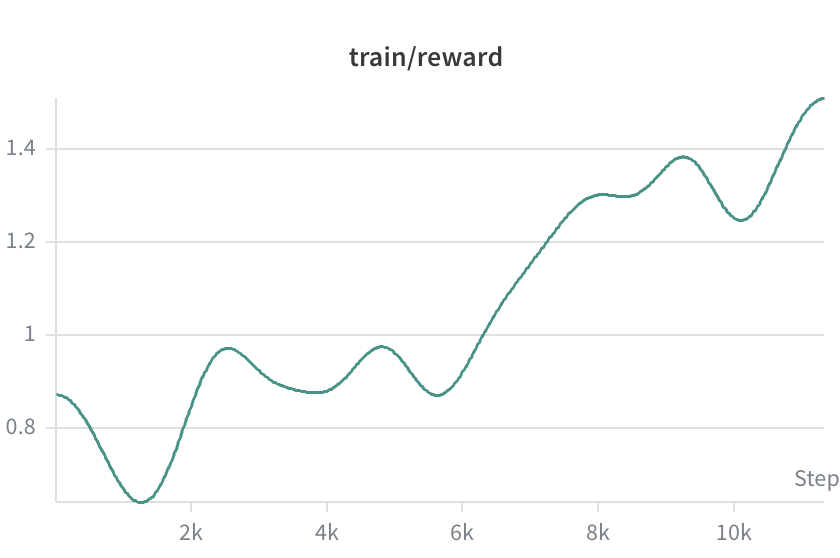
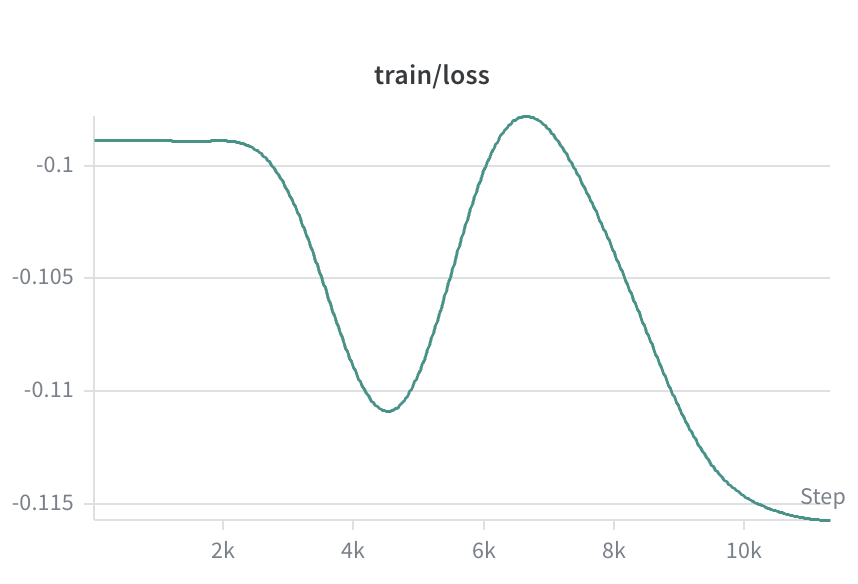
The reward function begins a noticeable climb after 6K steps, which aligns well with the trend observed in loss. Training took roughly 12 hours on an A100 GPU in Google Colab.
The adapter was pushed to Hugging Face:
hanzla/Qwen3.5-4B-mathvista-GRPO-adapter
Evaluation
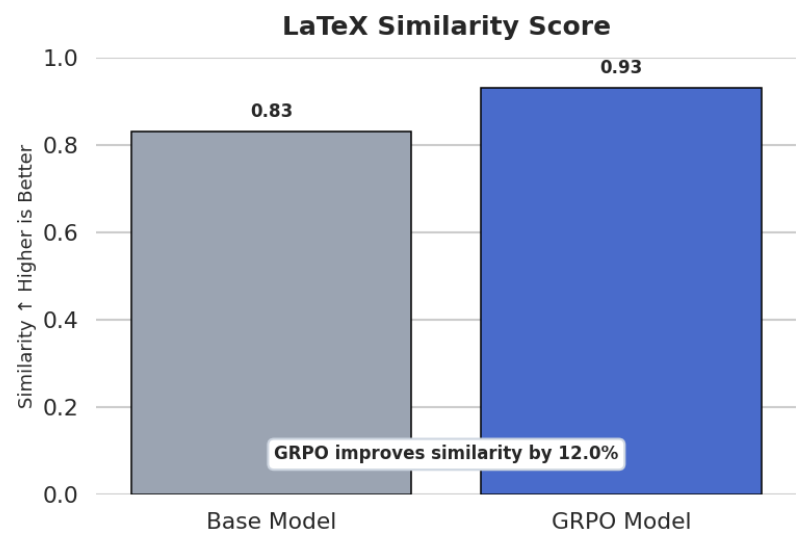
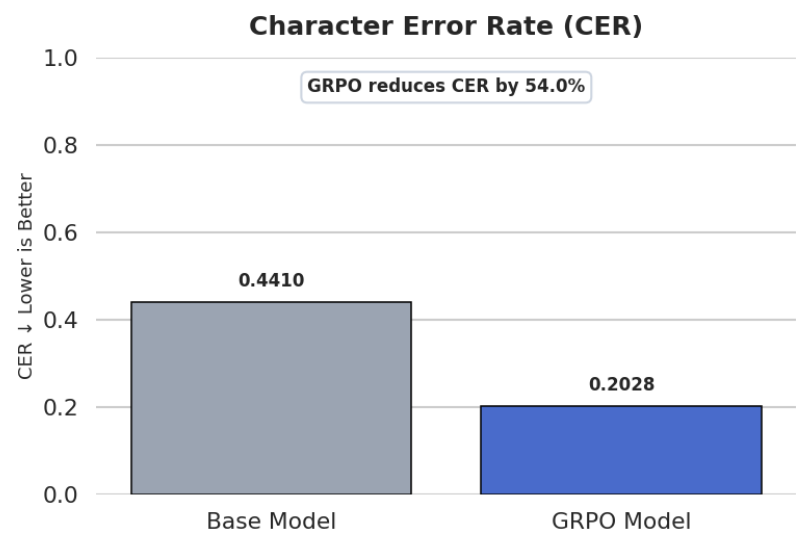
The goal was to compare the base model and the GRPO-trained model on a different but related task: transcribing mathematical expressions from images into LaTeX. I chose a sample of 100 questions from the test set of the LaTeX OCR dataset by Unsloth.
Final Words
This experiment was a small but interesting signal that GRPO can do more than improve the exact task it is trained on. By optimizing visual mathematical reasoning, the model also became noticeably better at LaTeX OCR, suggesting that some learned structure transferred across tasks.
The most interesting part for me was that the reward functions were not directly built for LaTeX OCR evaluation, yet the model still improved on that downstream task.